Running compute jobs#
Now that we’ve SSHed in, we’re connected to Picotte—but Picotte, like we saw in
the Introduction, is composed of many computers. SSHing into
picottelogin.urcf.drexel.edu just connects us to one of them, the so-called
“login node” (“node” just means one of the computers that make up the cluster).
But Picotte has nearly 100 nodes in it—how do we access the others?
The login node is a gateway to where the real work happens—the other nodes of the cluster, which are called “compute nodes”. You can think of this like a busy medical office. The login node is the waiting room, and the compute nodes are the examination rooms (where the work actually happens).
To access the compute nodes we need to submit a request to the scheduler. The scheduler accepts requests for the cluster to do some work (called jobs), keeps track of all pending jobs, and assigns them to compute nodes to run as capacity becomes available. The scheduler helps ensure that the cluster’s resources are used fairly by balancing competing requests from different users and research groups[1].
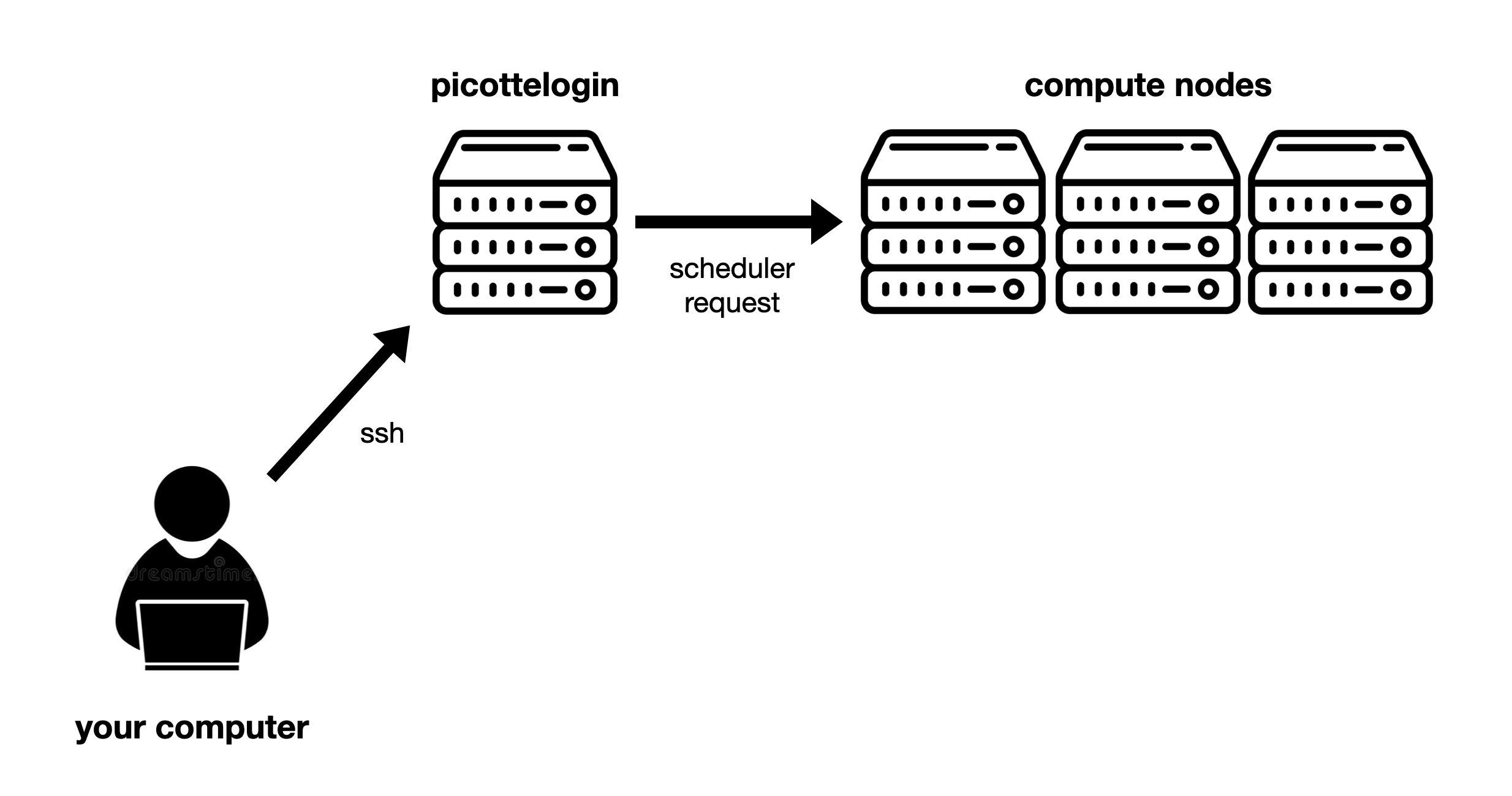
Fig. 7 Overview of Picotte access: From your computer, you access the login node using SSH. From there, you access the compute nodes by submitting requests to the scheduler.#
Our first job#
The scheduler used by Picotte is called SLURM. SLURM has many commands, we’ll learn a few of the most important today.
SLURM commands generally start with the letter s. Let’s run our first SLURM
command, sinfo:
sinfo
sinfo prints output that shows that status of all the nodes in the cluster.
It’s pretty dense, with a lot of information. Don’t worry about all of it for
now. We’re just looking to see that there are nodes in the idle or mixed
state in the def-sm partition. If there aren’t, that means the cluster is
busy, and we might have to wait a while to run our job.
Let’s run our first job, using the following command[2]:
srun --partition=def-sm --account=workshopprj --pty /bin/bash
You should see something like this:
[jjp366@picotte001 ~]$ srun --partition=def-sm --account=workshopprj --pty /bin/bash
srun: job 11702109 queued and waiting for resources
srun: job 11702109 has been allocated resources
[jjp366@node038 ~]$
Importantly, you will see the prompt change. Previously, the prompt was
<your username>@picotte001, because you were on the login node. Now, you
are on a compute node—in this case, node038 (you might be on a different
compute node).
Now we’re finally where the real work happens! From here, you can run any other commands your research requires—a Python script you wrote, open-source bioinformatics tools, commercial structural analysis software—the sky’s the limit. We have a lot of research software pre-installed on Picotte for you to use.
However, an interactive job like this might not be the best way to get work done. More on that later, for now let’s break down exactly what each of the arguments in the command above means and why we need them:
srun
The base command: this launches a single job on a compute node.
/bin/bash
sruntakes one argument: the command to run.bin/bashis the command to start a newbashshell.
--pty
This option is short for “pseudo-terminal”, this lets you run commands interactively rather than in a non-interactive batch mode (which we’ll learn more about later).
--partition=def-sm and --account=workshopprj
These options specify the account and partition the job should run under. These concepts merit more explanation in the next section.
Accounts and partitions#
Our first job submission immediately showed us two of the most important SLURM
concepts: accounts (the --account argument) and partitions (the --partition
argument).
Accounts#
Confusingly, this is not your Picotte user account. SLURM has a separate
concept of “bank accounts” which is what’s referred to here. You’ll also see
these referred to as “SLURM accounts” or “projects” (and they typically end in
prj).
Every job submitted to the scheduler has to be associated with a single SLURM account, which will be billed for the job’s usage.
Typically, each research group has two projects:
groupnameprjfor paid, priority tier jobsgroupnamefreeprjfor free-tier jobs
For this workshop, we’re all just using workshopprj which can only run
free-tier jobs. Picotte has two “tiers” of access, free and priority. You can
read more about Picotte usage rates and tiers on our documentation
site.
You can see all the SLURM accounts you have access to using the command:
sacctmgr show user $USER withassoc
Partitions#
A “partition” is a group of compute nodes. Partitions are also sometimes called “queues” or “job queues”, because jobs are scheduled separately on different partitions, so each is sort of has it’s own “queue” of jobs waiting to run.
Partitions are typically groups of nodes with similar hardware. For example, the
gpu partition includes all Picotte nodes with GPUs, and the bm partition
(“big memory”) has nodes with much more memory than the typical compute node.
Partitions also can have different access policies, resource limits, and billing. For example:
def-smis the standard free-tier partition. All free-tier projects have access, and jobs run here are not billed for, but this partition has small resource limits.defis the standard priority-tier partition. Only funded projects have access, and jobs must be paid for, but the resource limits ofdef-smare removed.
All jobs must specify a partition to run in. Here we used the def-sm
partition, which is for standard free-tier jobs. You can read more about all the
available partitions
here.
Let’s now exit the compute node and return to the login node:
exit
This will bring you back to the login node. See how your prompt has changed back
to picotte001. It is important to note that you have to be on a login node to
request a compute node. One you are on the compute node, if you want to go to
another compute node, you have to exit first.
Picotte is a shared resource
Please be considerate of others when submitting jobs. Remember that Picotte is a shared resource. Don’t request resources you don’t plan on actually using.
Don’t run computations on the login node
When using Picotte, you shouldn’t run heavy computations on the login node, because the login node is shared between everyone who logs into Picotte, so your computations will interfere with other people’s login processes. Once in a job, you can do whatever you want, because the resources assigned to your job (CPUs, memory, etc.) are given to it exclusively, so you won’t interfere with anyone else.